Купон на скидку: 2026

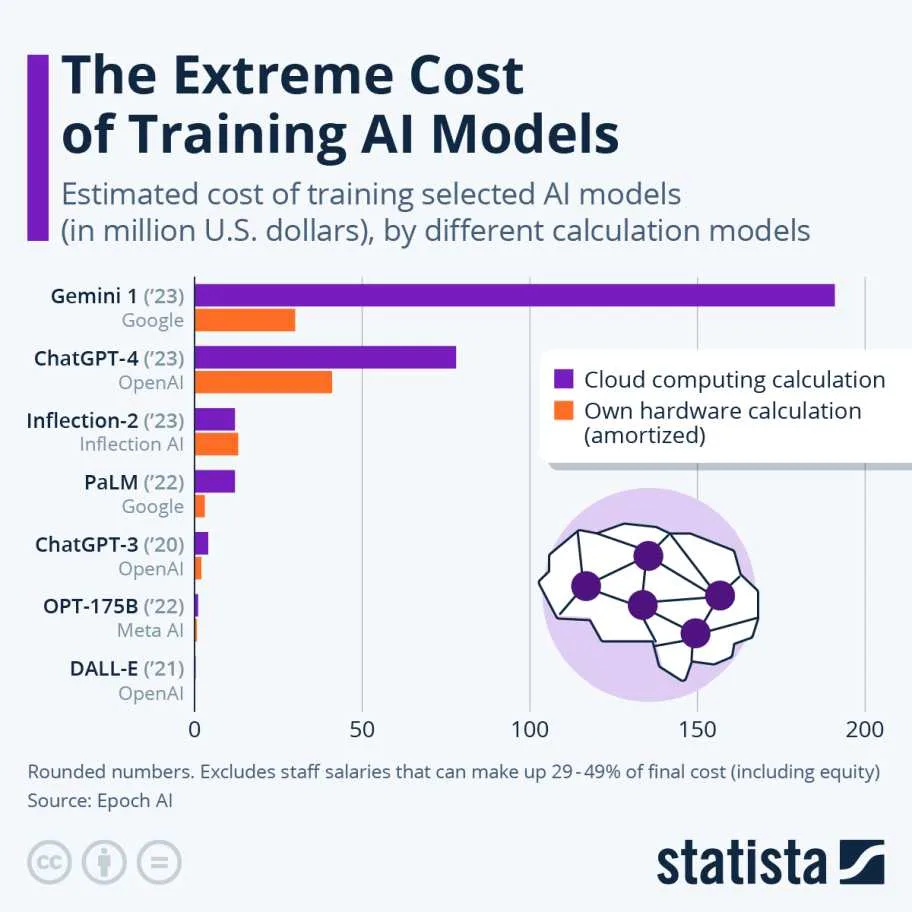
Растущие затраты уже заставили пользователей обратить внимание на более мелкие и дешевые модели. Это новое явление в мире покупок моделей с учетом затрат, и пока неясно, как оно повлияет на индустрию, но, вероятно, влияние будет значительным. Одно из предсказаний, наиболее четко изложенное соучредителем Coinbase Брайаном Армстронгом, заключается в том, что подавляющее большинство задач перейдет на более дешевые модели. Армстронг написал в X: "Спрос на интеллект практически бесконечен, но 80% рабочих нагрузок будут выполняться на моделях, которые на 99% дешевле, в течение 12-18 месяцев. 20% рабочих нагрузок все еще будут выполняться на моделях последнего поколения, где важно максимальное IQ". Если предсказание Армстронга сбудется, это будет значительным сдвигом для индустрии ИИ.
До сих пор большинство компаний в области ИИ конкурировали на основе качества, что означало использование самых передовых доступных моделей. Если те же задачи могут выполняться более дешевыми моделями без потери качества, это приведет к значительному изменению экономики ИИ. И, что важно, большая часть экономии будет происходить за счет крупных лабораторий, что нанесет финансовый удар по OpenAI и Anthropic как раз в тот момент, когда они готовятся к IPO. Это потенциально сейсмическое изменение в индустрии, основанное на одном простом вопросе: готовы ли компании перейти на более мелкие модели?
Начальные тесты показывают, что, если система правильно организована, более дешевые модели могут заменить более дорогие без ущерба для качества. В недавнем тесте, проведенном инструментом юридического ИИ Harvey, компании удалось снизить затраты на вывод в три раза без снижения качества. Тест, проведенный в партнерстве с платформой вывода Fireworks AI, комбинировал Claude Opus и Fireworks’ GLM 5.1, и переключался на Opus для самых интенсивных задач. Результатом стала значительно меньшая нагрузка в терминах серверного времени и общих затрат. "Качество на первом месте, и в юридической сфере так будет всегда", — сказал соучредитель Harvey Гейб Перейра в интервью TechCrunch, имея в виду услуги юридического ИИ, которые предоставляет его стартап.
Эта тенденция часто рассматривается в терминах крупных лабораторий против китайских моделей или моделей с открытым весом, но это упускает более важный момент. Реальное разделение не между собственными и открытыми моделями, а между большими и малыми моделями. Можно сэкономить, перейдя с GPT-5.5 на DeepSeek’s V4 Flash, но переход на GPT-5.4-mini работает так же хорошо. Ведется активная ценовая война между внутренним выводом крупных лабораторий и независимыми моделями с открытым весом. Для более крупного вопроса о малых и больших моделях не имеет значения, какая из малых моделей победит. Все это может показаться очевидным — конечно, не стоит использовать больше вычислительных ресурсов, чем необходимо, — но это противоречит подходу, ориентированному на масштабирование, который доминировал в индустрии до сих пор. Вдохновленные горьким уроком, лаборатории активно занимались обучением максимально вычислительно сложных моделей, продвигая границы возможностей ИИ. С ценами, сильно субсидируемыми инвесторами, у клиентов не было причин выбирать что-то кроме самого передового варианта. С ростом цен на токены и замедлением субсидий пользователи впервые сталкиваются с давлением затрат. Мы не знаем, приведет ли новое давление затрат к тому, что корпоративные пользователи перейдут на более мелкие модели. Они могут также сэкономить, делая меньше вызовов, используя меньше контекста или просто отказываясь от наименее перспективных развертываний. Но если окажется, что большинство развертываний может быть выполнено так же хорошо на более мелкой модели, это может серьезно снизить растущий спрос на вывод и поднять новые вопросы о том, как оправдать затраты на обучение передовой модели.